Vaatluse lähimad naabrid on sellised vaatlused, mis valitud tunnuse väärtuste mõttes on meid huvitavale vaatlusele kõige sarnasemad ehk asuvad sellele kõige lähemal. Läheduse määrab statistiline kaugus (Peatükk 16), mistõttu sarnasuse aluseks olevad tunnused peavad olema mõõdetud arvskaalal. Lähinaabrite meetodil ei ole muid eeldusi, aga tuleb arvestada, et liiga suure arvu tunnuste alusel kauguse mõõtmisega kaasnevad ka suured kaugused. Selle tulemusel ei pruugi kaugused enam vaatluste sarnasust hästi iseloomustada (curse of dimensionality).
Important
Lähinaabrid (k-nearest neighbors) tähendab igale vaatlusele kõige sarnasemate vaatluse valimist tunnuste ruumis lähtudes statistilisest kaugusest. Sealjuures peab olema eelnevalt määratud lähimate vaatluste arv \(k\). Vaatluste võrdlemisel lähimate naabritega saame prognoosida selliste tunnuste väärtusi, mida me ei kasutanud kauguste arvutamisel.
Lähinaabrite meetodit võib niisiis käsitleda ka statistilise mudeli või vähemalt algoritmina, milles sisendtunnusteks on kauguse arvutamisel aluseks olevad tunnused. Kui ei ole teada mõni vaatluse väljundtunnuse väärtus, siis selle saab tuletada lähimate naabrite vastava tunnuse väärtuste alusel. Sealjuures on prognoosimisel tegemist klassifitseerimisega nimiskaalal väljundtunnuse korral ja regressiooniga kui väljundtunnus on arvskaalal.
Lähinaabrite meetodi rakendamine prognoosimiseks koosneb alljärgnevatest sammudest.
Valime lähimate naabrite arvu \(k\). Kõige sobivama \(k\) leidmiseks saame kogu tegevust erinevate \(k\) väärtustega korrata ja valida sellise \(k\), mis annab kõige täpsema prognoosi.
Arvutame kõikide vaatluste vahel Eukleidilise kauguse tunnuste ruumis.
Määrame igale vaatlusele arvu \(k\) lähimad vaatlused.
Nimiskaalal väljundtunnuse korral määrame igale vaatlustele naabrite seas kõige sagedasema nimitunnuse väärtuse. Arvskaalal väljundtunnuse puhul on prognoos aga naabrite väärtuste nt aritmeetiline keskmine.
Lähinaabrite meetodi alusel prognoosimise puuduseks on prognooside sõltuvus arvust \(k\). Samuti on meetod arvutuslikult kulukas, sest iga vaatluse kohta tuleb kõik kaugused teistest vaatlustest eraldi leida.
Kasutame järgnevas näites andmeid iirise taimede erinevate osade suuruste ja liigi kohta. Vaatame esimesi ridu ja loetleme liikide esinemissagedused.
Andmetabelis on õietupe (sepal) ja õiekrooni (petal) pikkused ja laiused ning liik (Species). Sagedustabelist ilmneb, et 20 taime puhul on liik teadmata.
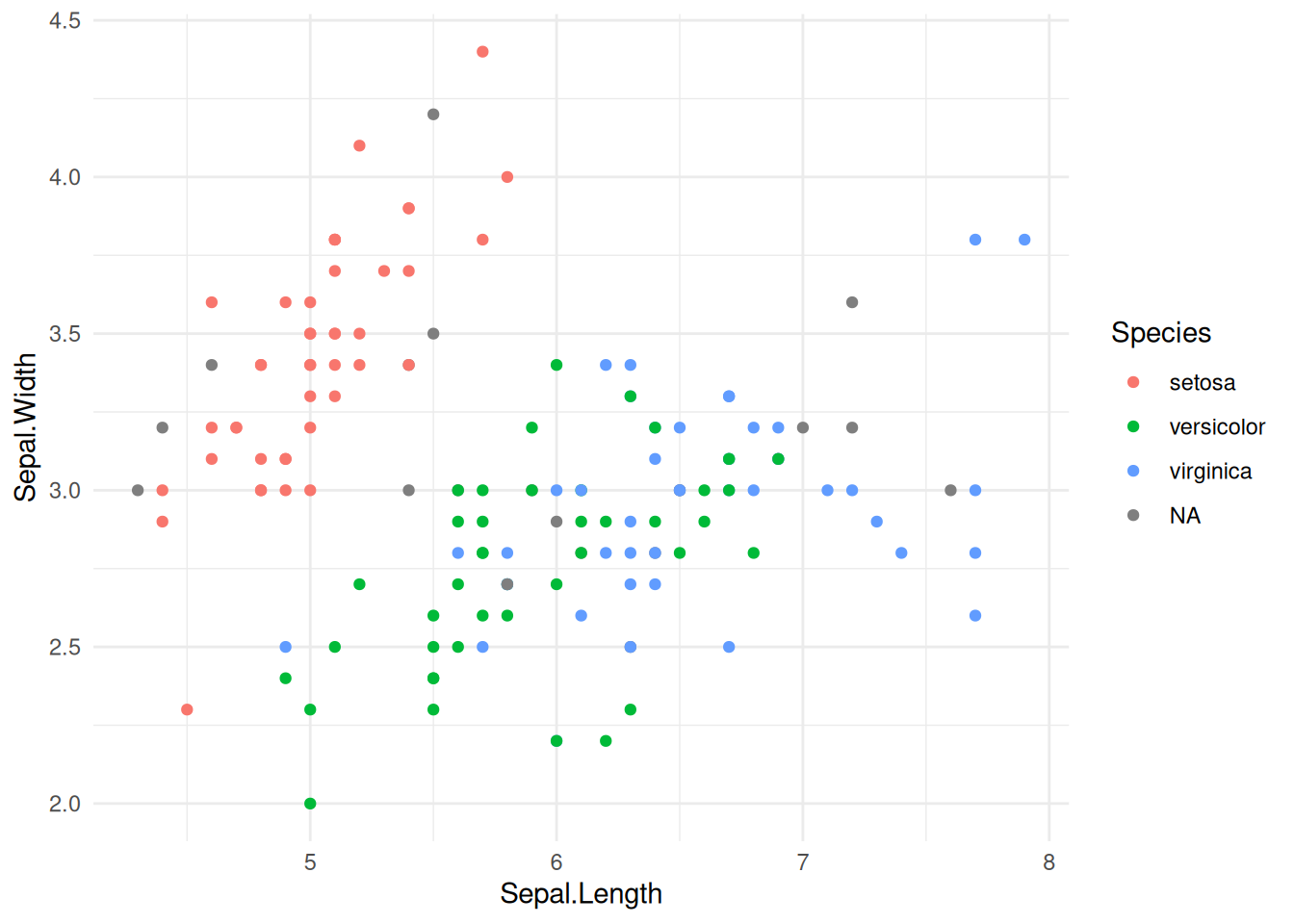
Uurime seost õietupe suuruste ja liigi vahel.
library('ggplot2')ggplot(iris) +aes(x = Sepal.Length, y = Sepal.Width, color = Species) +geom_point() +theme_minimal()
Joonis 25.1: Hajuvusjoonis õietupe mõõtmete kohta.
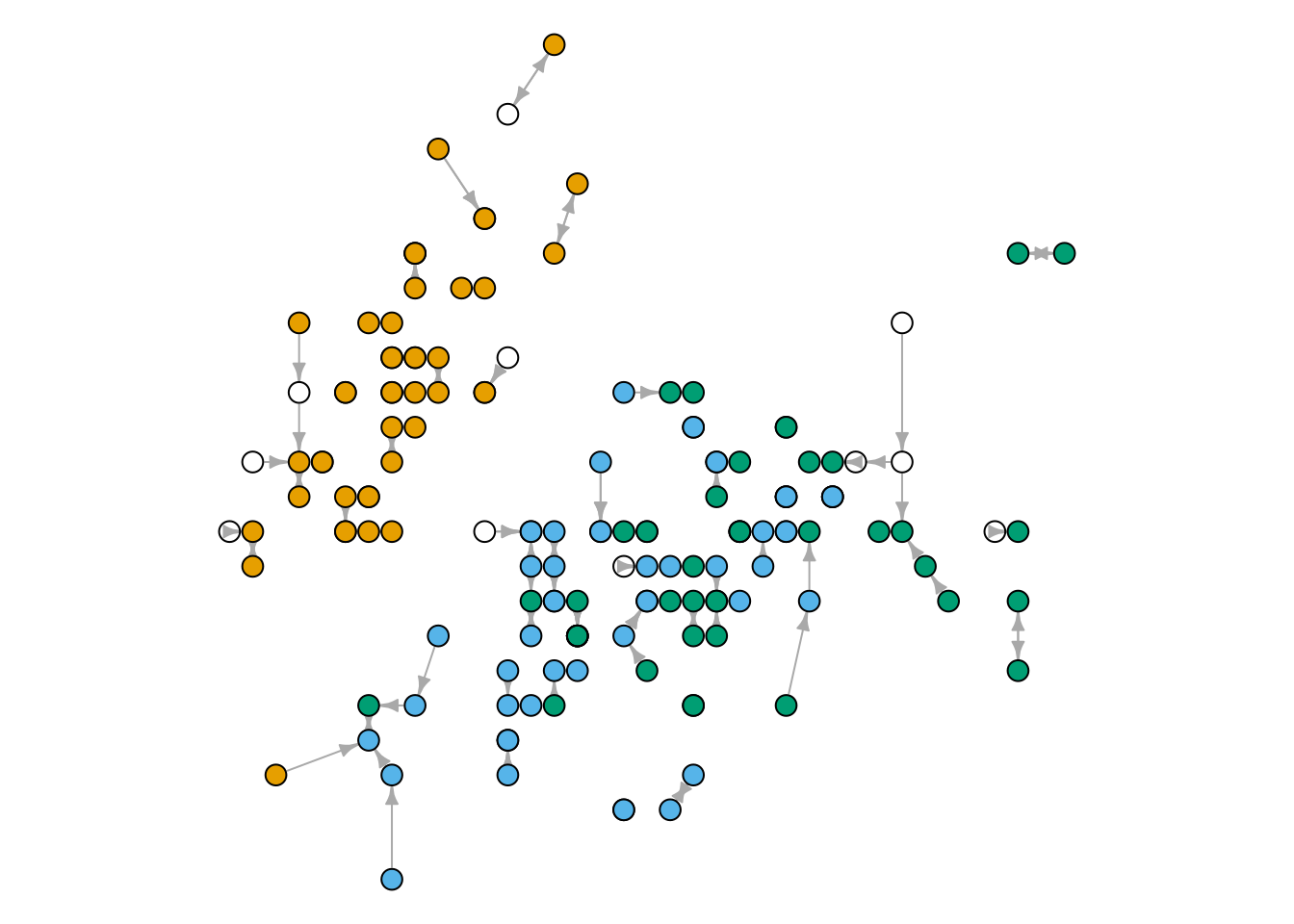
Näeme, et õietupe mõõtmete alusel on võimalik teatud juhtudel tuletada liik. Kasutame laiendusest cccd funktsiooni nng(), et leida ja joonistada iga punkti üks lähim naaber (\(k = 1\)).
Joonis 25.2: Iirise taimede lähimad naabrid \(k = 1\) korral.
Joonisel Joonis 25.2 on valgega tähistatud need taimed, mille liik on teadmata. Määrame selle liigi lähima naabri liigi alusel, kasutades funktsiooni knn laiendusest class. Selleks peame funktsiooni argumentidena andma sisendtunnuste väärtused eraldi teada olevate ja teadmata liikidega ridade kohta. Samuti peame andma liigid nende ridade kohta, kus see on teada.
library('class')ln <-knn(train = iris[!is.na(iris$Species), 1:2], # Teada liigiga readtest = iris[is.na(iris$Species), 1:2], # Teadmata liigiga readcl = iris[!is.na(iris$Species), 'Species'], # Teada liigidk =1) # Naabrite arvln